Hashmap的结构,1.7和1.8有哪些区别
本文共 883 字,大约阅读时间需要 2 分钟。
不同点:
(1)JDK1.7用的是头插法,而JDK1.8及之后使用的都是尾插法,那么他们为什么要这样做呢?因为JDK1.7是用单链表进行的纵向延伸,当采用头插法时会容易出现逆序且环形链表死循环问题。但是在JDK1.8之后是因为加入了红黑树使用尾插法,能够避免出现逆序且链表死循环的问题。(2)扩容后数据存储位置的计算方式也不一样:1. 在JDK1.7的时候是直接用hash值和需要扩容的二进制数进行&(这里就是为什么扩容的时候为啥一定必须是2的多少次幂的原因所在,因为如果只有2的n次幂的情况时最后一位二进制数才一定是1,这样能最大程度减少hash碰撞)(hash值 & length-1)
2、而在JDK1.8的时候直接用了JDK1.7的时候计算的规律,也就是扩容前的原始位置+扩容的大小值=JDK1.8的计算方式,而不再是JDK1.7的那种异或的方法。但是这种方式就相当于只需要判断Hash值的新增参与运算的位是0还是1就直接迅速计算出了扩容后的储存方式。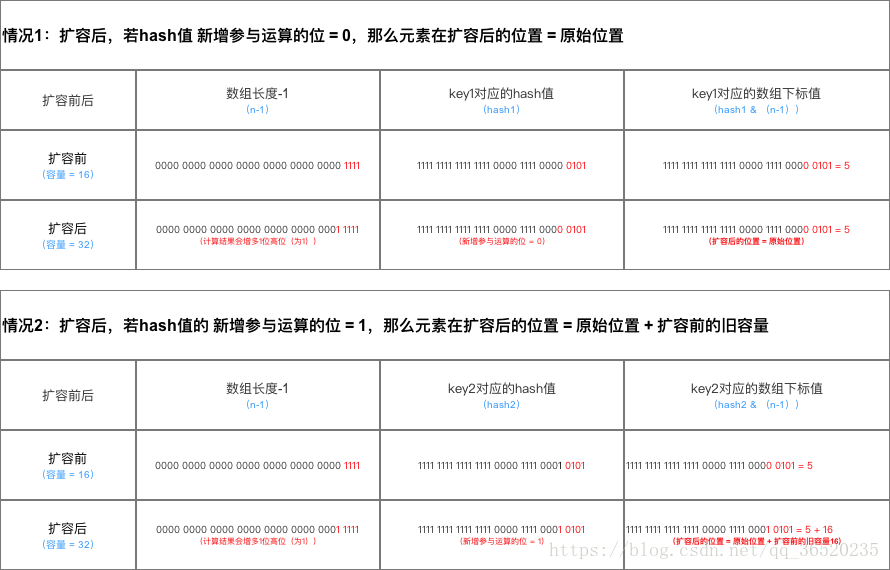
在计算hash值的时候,JDK1.7用了9次扰动处理=4次位运算+5次异或,而JDK1.8只用了2次扰动处理=1次位运算+1次异或。
扩容流程对比图:
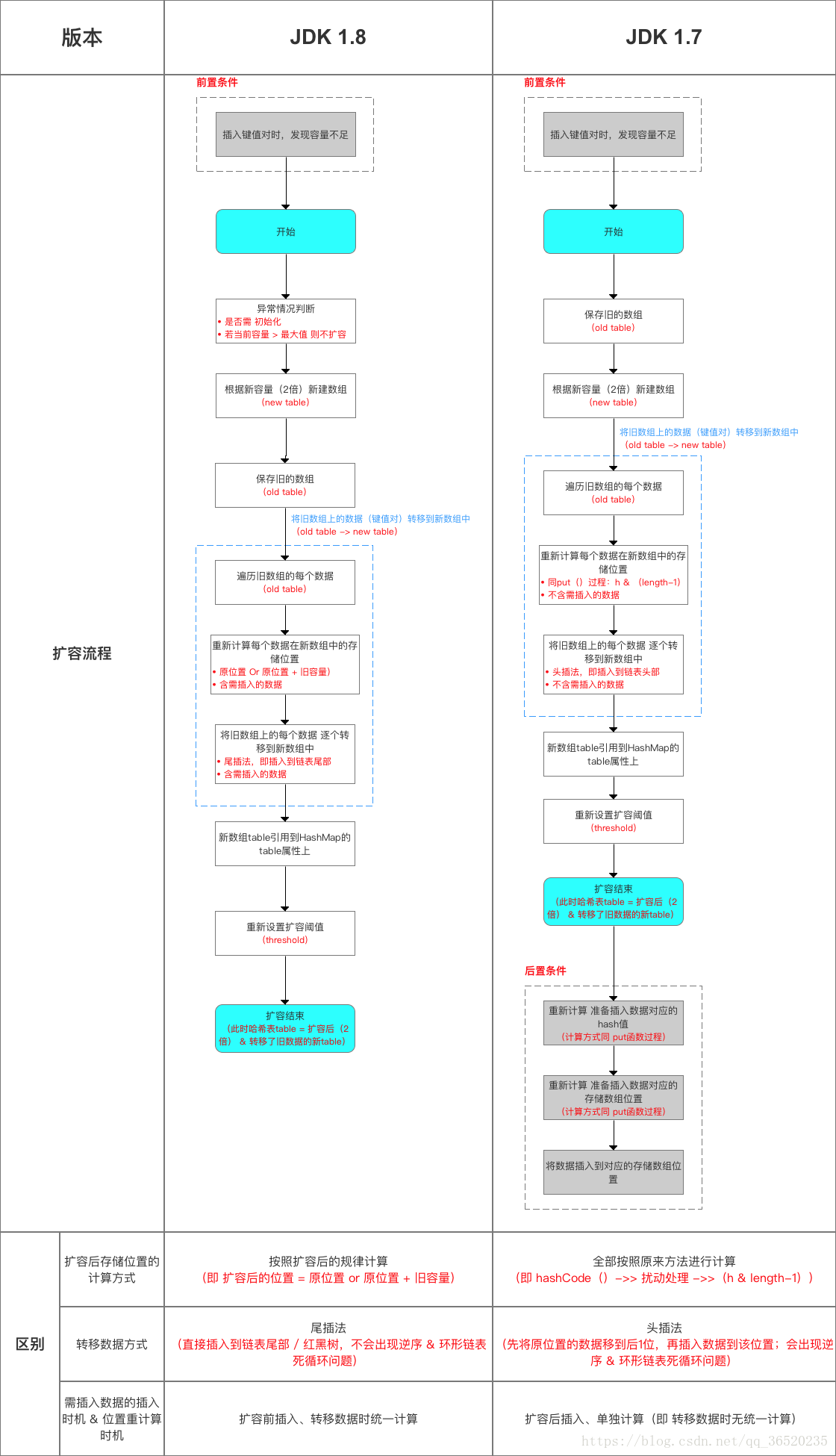
(3)JDK1.7的时候使用的是数组+ 单链表的数据结构。但是在JDK1.8及之后时,使用的是数组+链表+红黑树的数据结构(当链表的深度达到8的时候,也就是默认阈值,就会自动扩容把链表转成红黑树的数据结构来把时间复杂度从O(n)变成O(nlogN)提高了效率)
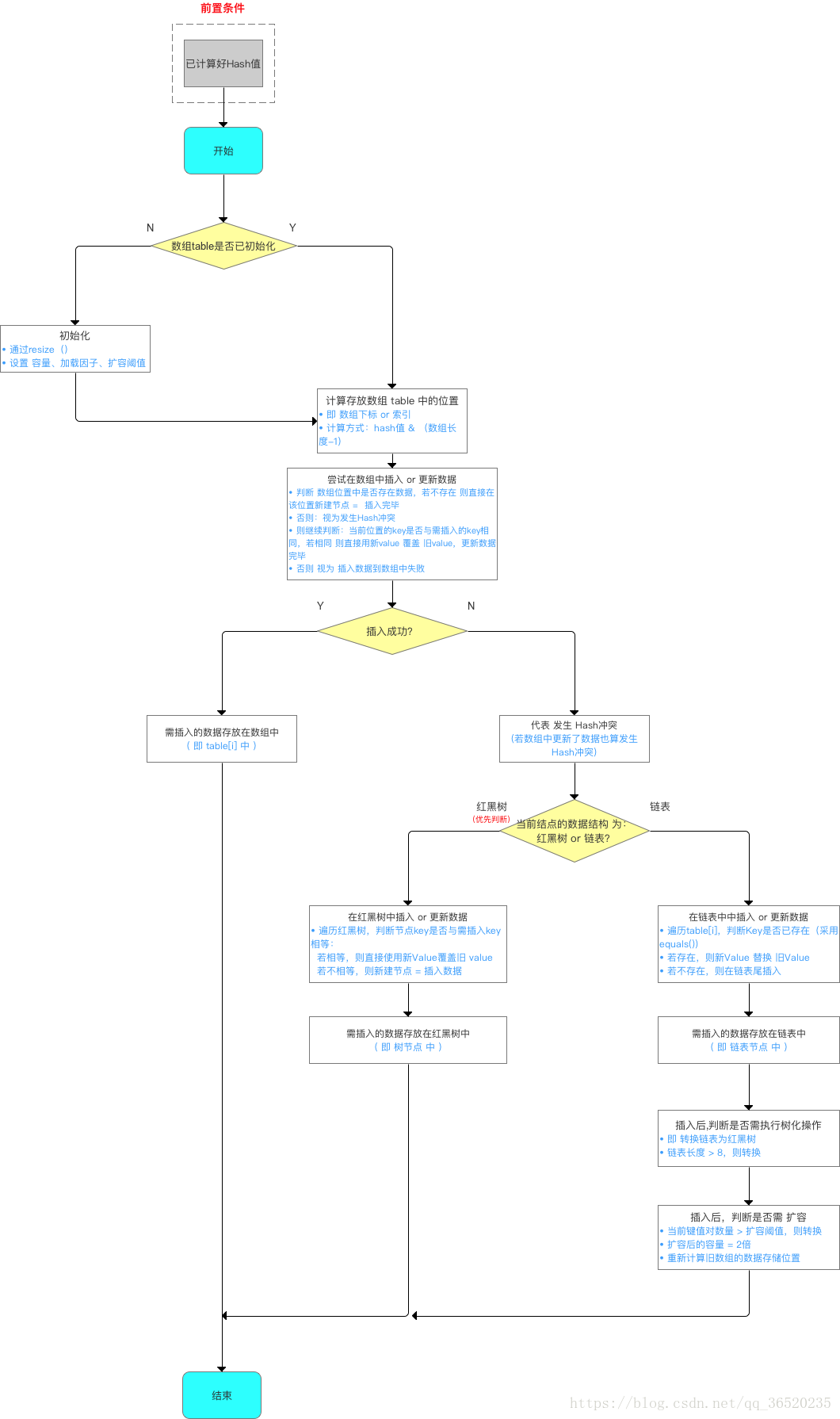
(二)哈希表如何解决Hash冲突?
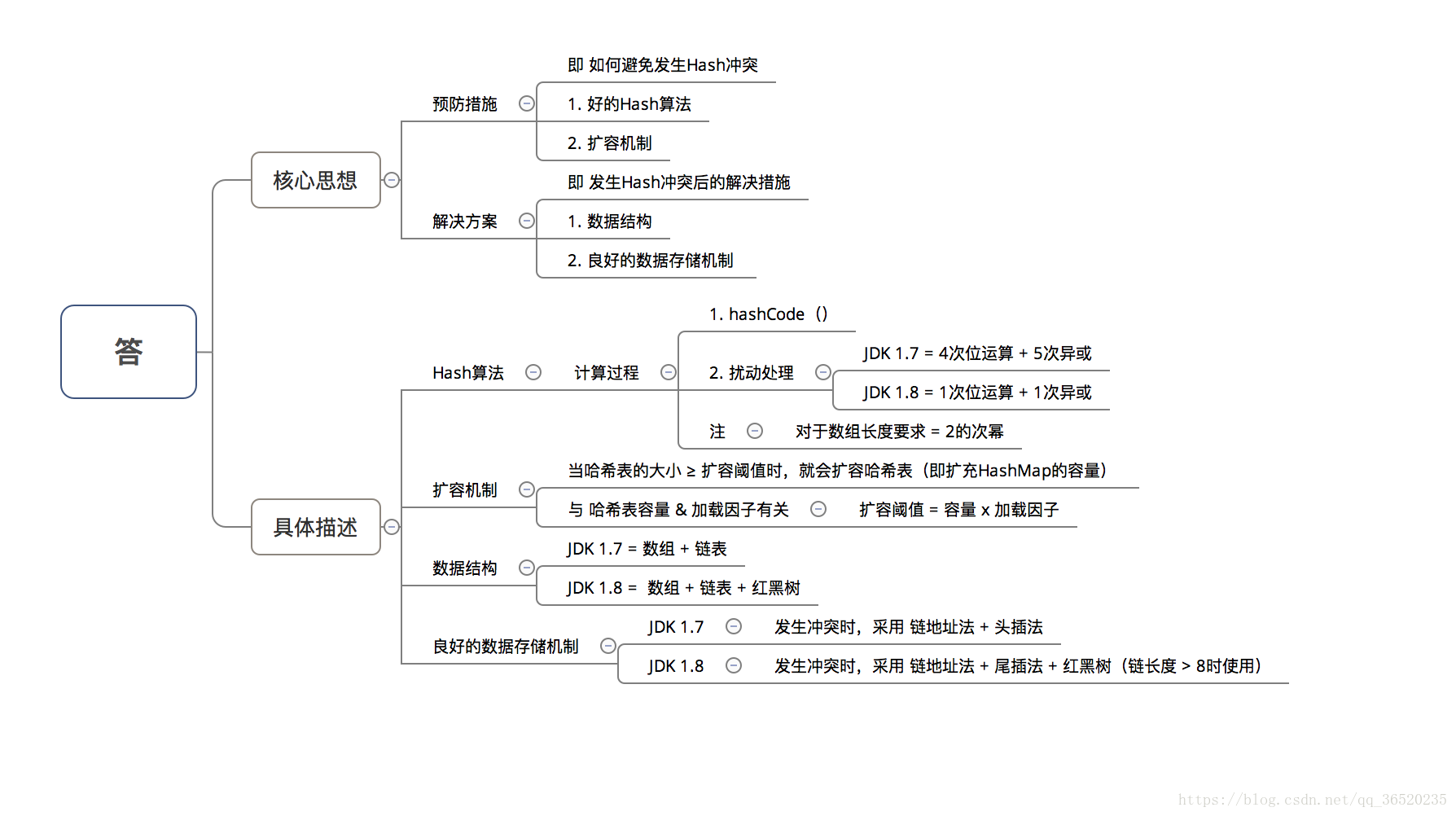
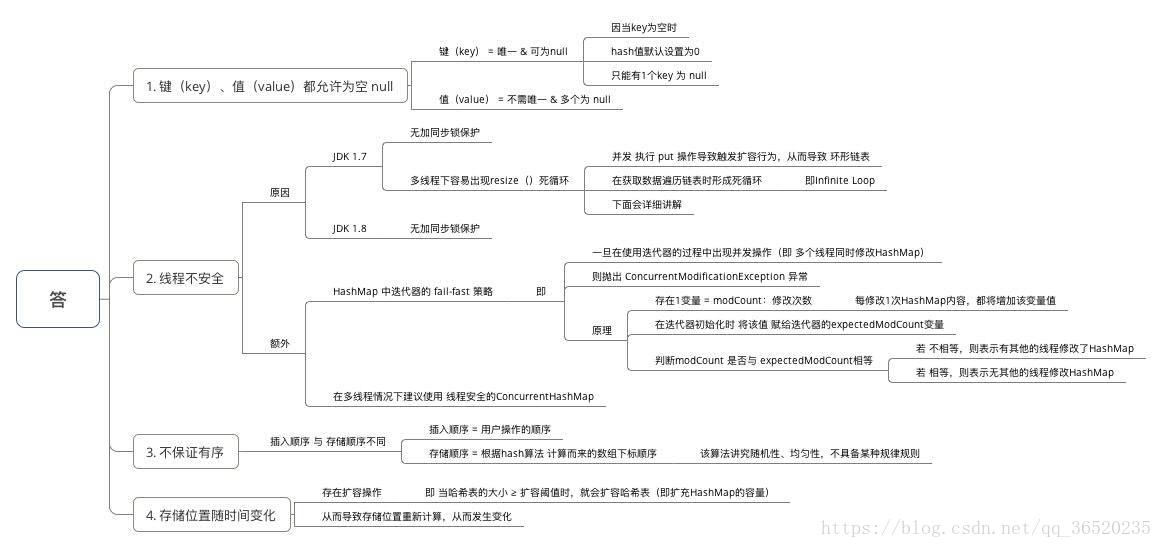
(三)为什么HashMap具备下述特点:键-值(key-value)都允许为空、线程不安全、不保证有序、存储位置随时间变化
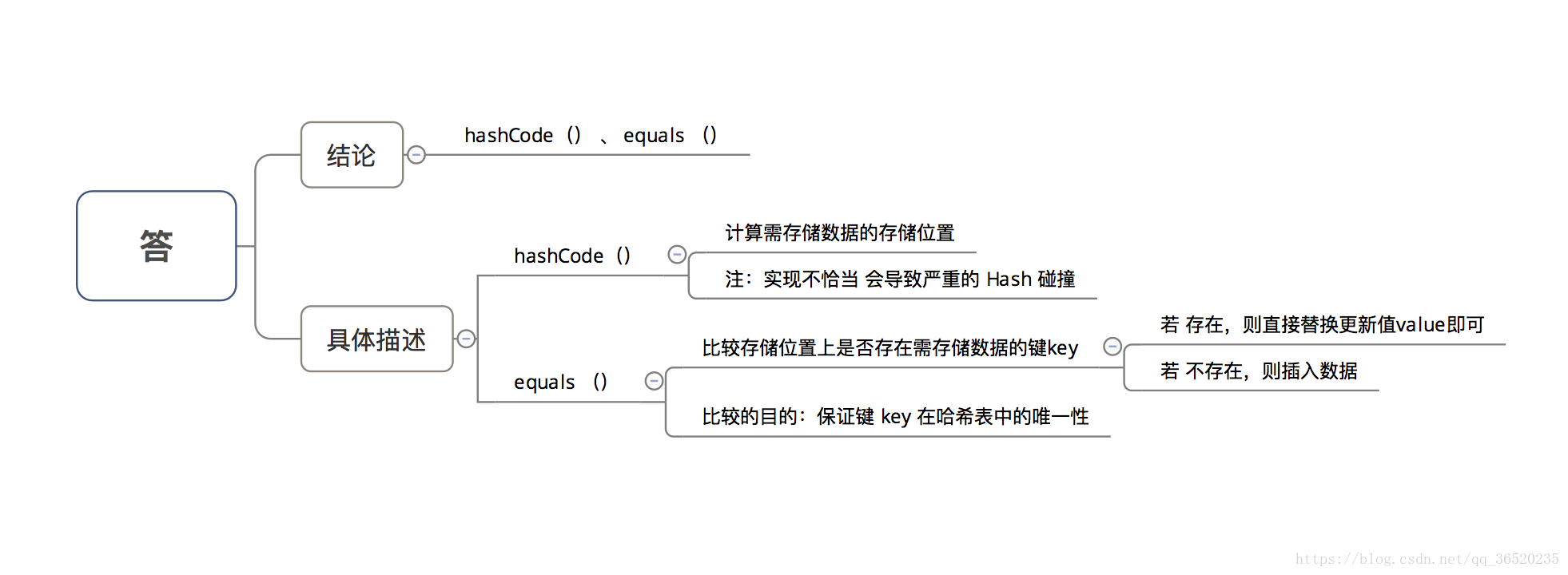
(五)HashMap 中的 key若 Object类型, 则需实现哪些方法?
你可能感兴趣的文章
springCloud升级到Finchley.RELEASE,SpringBoot升级到2.0.4
查看>>
Spring boot + Arthas
查看>>
omitted for duplicate jar包冲突排查
查看>>
如何保证缓存与数据库的双写一致性?
查看>>
java.lang.ArrayStoreException: sun.reflect.annotation.TypeNotPresentExceptionProxy排查
查看>>
深浅拷贝,深浅克隆clone
查看>>
Java基础零散技术(笔记)
查看>>
Mysql优化sql排查EXPLAIN EXTENDED
查看>>
线程之间数据传递ThreadLocal,InheritableThreadLocal,TransmittableThreadLocal
查看>>
spring循环依赖,解决beans in the application context form a cycle
查看>>
分布式锁的实现
查看>>
解决POJO的属性首字母为大写,但是赋值不了的问题
查看>>
服务器运维整理(笔记)
查看>>
redis分布式锁在MySQL事务代码中使用,没控制好并发原因
查看>>
centos7中的网卡一致性命名规则、网卡重命名方法
查看>>
能切换环境的python
查看>>
Tmux 使用教程
查看>>
DLINK-DSN1100的安装使用记录
查看>>
openssl的学习
查看>>
watchguard ssl100恢复出厂化设置
查看>>